 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI for Mycetoma Diagnosis in Histopathological Images: The MICCAI 2024 Challenge
Dec 25, 2025



Mycetoma is a neglected tropical disease caused by fungi or bacteria leading to severe tissue damage and disabilities. It affects poor and rural communities and presents medical challenges and socioeconomic burdens on patients and healthcare systems in endemic regions worldwide. Mycetoma diagnosis is a major challenge in mycetoma management, particularly in low-resource settings where expert pathologists are limited. To address this challenge, this paper presents an overview of the Mycetoma MicroImage: Detect and Classify Challenge (mAIcetoma) which was organized to advance mycetoma diagnosis through AI solutions. mAIcetoma focused on developing automated models for segmenting mycetoma grains and classifying mycetoma types from histopathological images. The challenge attracted the attention of several teams worldwide to participate and five finalist teams fulfilled the challenge objectives. The teams proposed various deep learning architectures for the ultimate goal of this challenge. Mycetoma database (MyData) was provided to participants as a standardized dataset to run the proposed models. Those models were evaluated using evaluation metrics. Results showed that all the models achieved high segmentation accuracy, emphasizing the necessitate of grain detection as a critical step in mycetoma diagnosis. In addition, the top-performing models show a significant performance in classifying mycetoma types.
ViT-2SPN: Vision Transformer-based Dual-Stream Self-Supervised Pretraining Networks for Retinal OCT Classification
Jan 28, 2025Optical Coherence Tomography (OCT) is a non-invasive imaging modality essential for diagnosing various eye diseases. Despite its clinical significance, developing OCT-based diagnostic tools faces challenges, such as limited public datasets, sparse annotations, and privacy concerns. Although deep learning has made progress in automating OCT analysis, these challenges remain unresolved. To address these limitations, we introduce the Vision Transformer-based Dual-Stream Self-Supervised Pretraining Network (ViT-2SPN), a novel framework designed to enhance feature extraction and improve diagnostic accuracy. ViT-2SPN employs a three-stage workflow: Supervised Pretraining, Self-Supervised Pretraining (SSP), and Supervised Fine-Tuning. The pretraining phase leverages the OCTMNIST dataset (97,477 unlabeled images across four disease classes) with data augmentation to create dual-augmented views. A Vision Transformer (ViT-Base) backbone extracts features, while a negative cosine similarity loss aligns feature representations. Pretraining is conducted over 50 epochs with a learning rate of 0.0001 and momentum of 0.999. Fine-tuning is performed on a stratified 5.129% subset of OCTMNIST using 10-fold cross-validation. ViT-2SPN achieves a mean AUC of 0.93, accuracy of 0.77, precision of 0.81, recall of 0.75, and an F1 score of 0.76, outperforming existing SSP-based methods.
Validation of object detection in UAV-based images using synthetic data
Jan 17, 2022Object detection is increasingly used onboard Unmanned Aerial Vehicles (UAV) for various applications; however, the machine learning (ML) models for UAV-based detection are often validated using data curated for tasks unrelated to the UAV application. This is a concern because training neural networks on large-scale benchmarks have shown excellent capability in generic object detection tasks, yet conventional training approaches can lead to large inference errors for UAV-based images. Such errors arise due to differences in imaging conditions between images from UAVs and images in training. To overcome this problem, we characterize boundary conditions of ML models, beyond which the models exhibit rapid degradation in detection accuracy. Our work is focused on understanding the impact of different UAV-based imaging conditions on detection performance by using synthetic data generated using a game engine. Properties of the game engine are exploited to populate the synthetic datasets with realistic and annotated images. Specifically, it enables the fine control of various parameters, such as camera position, view angle, illumination conditions, and object pose. Using the synthetic datasets, we analyze detection accuracy in different imaging conditions as a function of the above parameters. We use three well-known neural network models with different model complexity in our work. In our experiment, we observe and quantify the following: 1) how detection accuracy drops as the camera moves toward the nadir-view region; 2) how detection accuracy varies depending on different object poses, and 3) the degree to which the robustness of the models changes as illumination conditions vary.
Comparative Validation of Machine Learning Algorithms for Surgical Workflow and Skill Analysis with the HeiChole Benchmark
Sep 30, 2021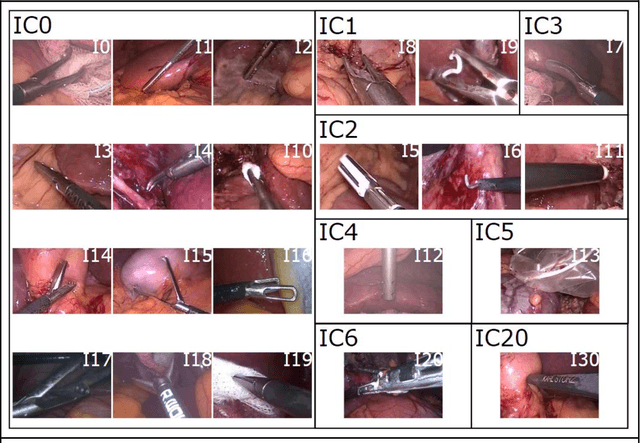
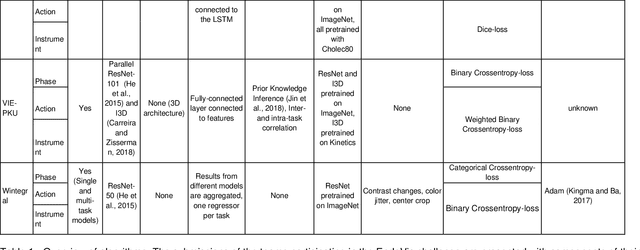
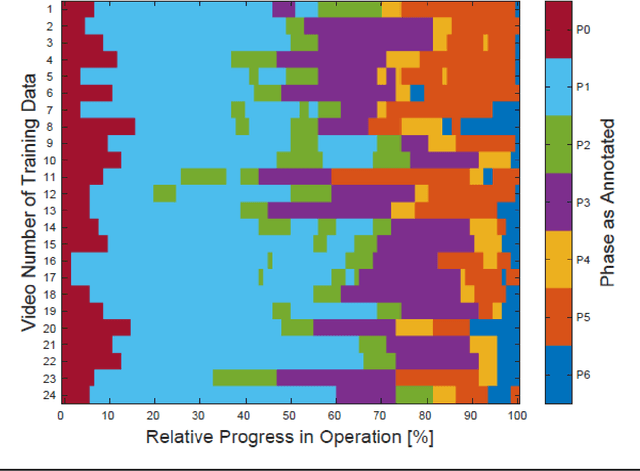
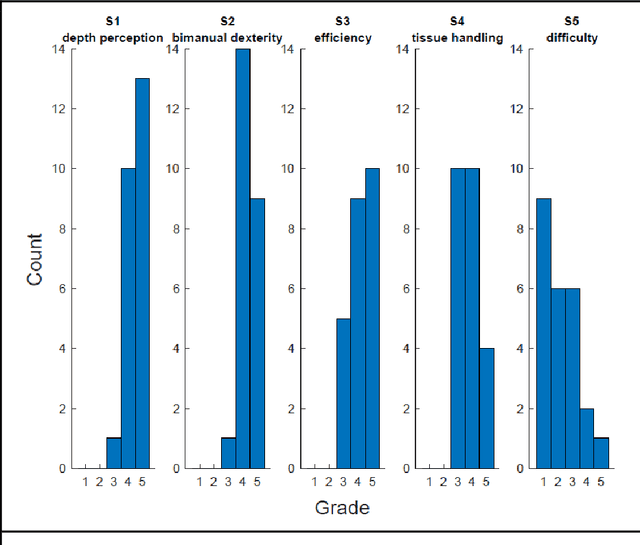
PURPOSE: Surgical workflow and skill analysis are key technologies for the next generation of cognitive surgical assistance systems. These systems could increase the safety of the operation through context-sensitive warnings and semi-autonomous robotic assistance or improve training of surgeons via data-driven feedback. In surgical workflow analysis up to 91% average precision has been reported for phase recognition on an open data single-center dataset. In this work we investigated the generalizability of phase recognition algorithms in a multi-center setting including more difficult recognition tasks such as surgical action and surgical skill. METHODS: To achieve this goal, a dataset with 33 laparoscopic cholecystectomy videos from three surgical centers with a total operation time of 22 hours was created. Labels included annotation of seven surgical phases with 250 phase transitions, 5514 occurences of four surgical actions, 6980 occurences of 21 surgical instruments from seven instrument categories and 495 skill classifications in five skill dimensions. The dataset was used in the 2019 Endoscopic Vision challenge, sub-challenge for surgical workflow and skill analysis. Here, 12 teams submitted their machine learning algorithms for recognition of phase, action, instrument and/or skill assessment. RESULTS: F1-scores were achieved for phase recognition between 23.9% and 67.7% (n=9 teams), for instrument presence detection between 38.5% and 63.8% (n=8 teams), but for action recognition only between 21.8% and 23.3% (n=5 teams). The average absolute error for skill assessment was 0.78 (n=1 team). CONCLUSION: Surgical workflow and skill analysis are promising technologies to support the surgical team, but are not solved yet, as shown by our comparison of algorithms. This novel benchmark can be used for comparable evaluation and validation of future work.